4. Databehandling
4.1 Datainnsamling fra panelhusstandene
PeopleMeter sender inn data til vårt Data Collection System (DCS) ved å koble seg til Internett via GPRS, og overføre krypterte data til DCS maskinene daglig ved TV-døgnets slutt. Hvert PeopleMeter er programmert til å kontakte DCS gjentatte ganger inntil dataleveransen er komplett. Etter komplett datainnsamling sendes data til dataprosesseringsverktøyet AtriaPro.
FocalMeter leverer data til vårt Data Collection System for FocalMeter direkte via panelhusstandens egen internettilkobling. Data overføres kontinuerlig i små porsjoner slik at det ikke påvirker husstandens bredbåndskapasitet. Det er kun data fra nettsider/avspillere i Whitelisten som vil bli overført. Denne datamengden er svært liten og overføres kryptert. Etter komplett datainnsamling sendes data til dataprosesseringsverktøyet AtriaPro.
Hver dag gjøres uttrekk av online konsum på tagget innhold i Censusdata for alle registrerte enheter i Panel A. Basert på FocalMeter og 4G-målingen oppdateres daglig en liste over alle DeviceIDs som kan finnes igjen i Censusdata.
RateOnAir leverer data til RateOnAir Data Collection System via 3G til Médiamétries nettsky hos hosting leverandøren Amazon Web Services, lokalisert i Irland. Amazon Web Services har internt egne systemer for backup av data. RateOnAir er satt opp til å levere data to ganger i døgnet. I tillegg er meteret programmert til å ringe inn ved lavt batteri eller ved tilkobling av lader. Denne funksjonaliteten gjør at vi mottar seerdata før meteret går tom for batteri.
4.2 Prosessering i AtriaPro
AtriaPro er et dataprosesserings- og panelstyringsverktøy som har blitt utviklet spesifikt for å møte kravene til prosessering av data fra elektroniske TV-undersøkelser. AtriaPro har et fleksibelt design og blir kontinuerlig tilpasset spesifikke krav eller løsninger. AtriaPro utgjør hjertet i produksjonssystemet som sørger for at innsamlede data fra panelhusstandene blir editert, validert, kvalitetssikret og vektet på daglig basis.
Prosesseringsverktøyet har en rekke funksjoner for å behandle de komplekse dataene fra de ulike måleteknologiene, slik som reformatering av data, kobling til masterfiler, datavalidering, editering, kontroll og rapportering for videre behandling og oppfølging.
AtriaPro inneholder også en rekke effektive kvalitetskontroller både for klassifisering av panelmedlemmer og for ubehandlede og prosesserte Audience Data. En av kjernefunksjonene i systemet er evnen til å utføre objektive dataanalyser. Hvis det kommer inn lite troverdige eller mangelfulle data fra en panelhusstand, enten det gjelder hardware eller atferd, vil systemet identifisere dette. Hvis en feil i meteret blir identifisert vil panelhusstanden automatisk bli tatt ut av det rapporterende panelet. Alle feilmeldinger blir registrert fra de oppstår og frem til de er løst. En beskrivelse av alle feilmeldinger blir lagret slik at det er mulig å følge med på historikken over feilmeldinger for hver panelhusstand.
AtriaPro har en rekke funksjoner for å behandle de komplekse dataene fra panelhusstandene. Noen av de viktigste funksjonene er:
- Reformatere rå statement som kommer fra meterne.
- Validere kanaler, skjermer, enheter og panelmedlemmer mottatt fra meterne mot gyldige enheter som finnes i paneldatabasen.
- Identifisere innhold/kanaler.
- Editering av data.
- Rapportering av data på personnivå.
- Identifisere potensielle eller faktiske feil.
- Validering av panelmedlemmer og panelhusstander.
- Vekting av paneldata til definerte universverdier.
- Produsere rapporter for videre oppfølging og behandling.
- Rapportere Audience Data i henhold til åpent filformat.
Gjennom denne prosessen vil mulige problem og faktiske feil bli oppdaget. Disse blir oppsummert og sendt videre til Panelsupport for videre oppfølging og kvalitetskontroll.
Det er også etablert rutiner for både automatiske og manuelle kontroller av sluttproduktet fra systemet.
4.3 Seing på personnivå
I panel A tildeles målte seertilfeller på TV-skjermen til personer i husstanden basert på knappetrykking på fjernkontrollen på PeopleMeteret. Dette gjelder både broadcast og online seing på den store skjermen, inkludert seing via fast tilkoblete enheter som set top box, spillkonsoller og strømmebokser. Det kan også gjelde seing via mobile enheter dersom de viser innhold på TV-skjermen.
For de mobile skjermene PC/Mac, nettbrett og mobil blir seingen tildelt personer i husstanden basert på modellering kalt PIV (probability of individual viewing):
- Seing på skjermer som er oppgitt å ha kun én bruker vil bli tilskrevet denne personen direkte.
- For skjermer som benyttes av flere personer, vil seingen bli tilskrevet personer i husstanden basert på modellering.
Modelleringen tar utgangspunkt i opplysninger den enkelte panelhusstand har oppgitt om hvem som bruker de ulike skjermene til ulike tidspunkt for å se ulike typer innhold. For hver skjerm er det angitt en hovedbruker/eier og hvorvidt den brukes av en eller flere personer.
For skjermer som deles mellom flere personer skal hver av brukerne angi hvilke typer innhold de ser på ulike tider på hverdag og helg. Med utgangspunkt i disse opplysningene kalkuleres sannsynligheter for seing per sjanger og daypart for hver bruker av enheten. Seertilfeller som er registrert på en delt enhet blir deretter tildelt personer basert på disse sannsynlighetene i følgende prioriterte rekkefølge:
- Match på sjanger og daypart på den aktuelle skjermen
- Match på daypart på den aktuelle skjermen
- Match på sjanger på den aktuelle skjermen
- Match på sjanger og daypart på andre skjermer i husstanden
- Match på daypart på andre skjermer i husstanden
- Match på sjanger på andre skjermer i husstanden
- Brukere av skjermen
Dersom modellen ikke finner sannsynligheter større enn 0 på øverste nivå, går den videre nedover lista inntil den finner sannsynligheter større enn 0. I siste instans blir seertilfellet tildelt brukere av skjermen basert på overordnet bruksandel per person.
Etter at modellen har tildelt seertilfellet til én person i husstanden, vil den deretter vurdere om det skal legges til flere samtidige seere i husstanden. Det kalkuleres sannsynligheter for samseing basert på oppgitt andel samseing samt hvert husstandsmedlems angitte bruk av hver enkelte device. Kommersielt innhold allokeres til seere med sjangeren til tilliggende program.
I panel B benyttes personlige RateOnAir og seertilfellene rapporteres direkte på personnivå.
4.4 Editeringsregler og validering av sample
4.4.1 Editering av data fra PeopleMeter
Tildeling av minutt
Seing på broadcast innhold på TV-skjermen målt med PeopleMeter rapporteres på minuttnivå. Den kanalen (inkludert off) som har majoriteten av minuttet tildeles hele minuttet. Usammenhengende sekunder for samme kanal innenfor minuttet akkumuleres. Dersom flere kanaler står likt, tildeles minuttet den kanalen som opptrer først i minuttet. For å bli regnet som TV-seer må et Panelmedlem være registrert som seer i majoriteten av minuttet. Ved lik lengde (30 sekunder) tildeles minuttet til personen basert på registrering i første halvdel av minuttet.
Tidsforsinket seing
Seing som identifiseres som minst 120 sekunder tidsforsinket gjennom Audio Watermarking og Audio Matching, blir rapportert som playback. Seing som er inntil 120 sekunder tidsforsinket rapporteres som live. Dette parameteret tar høyde for ulik forsinkelse av sendingen for forskjellige distributører, dekodere og plattformer.
Samtidig registrering på flere PeopleMeter
Dersom et panelmedlem glemmer å trykke seg ut fra et PeopleMeter og deretter prøver å trykke seg inn på et annet PeopleMeter, vil den siste registreringen aksepteres. Overlappende seing fjernes ved å avslutte den første seersesjonen på det tidspunktet den påfølgende sesjonen begynner.
Samsendinger
Ved simultane samsendinger mellom flere kanaler vil de kanalene som er enkodet bli identifisert ved hjelp av Watermarking som er unik per kanal. Ved samsending mellom kanaler som identifiseres med Audio Matching vil husstandens data kunne matche med flere referansekanaler. I slike tilfeller fordeles seingen mellom de involverte kanalene etter følgende regler:
- Inngående kanal: Seersesjoner som starter før samsendingen begynner tildeles den kanalen som var identifisert i forkant.
- Utgående kanal: Seersesjoner som begynte i samsendingen og fortsetter etter samsendingen er over tildeles den kanalen som identifiseres i etterkant.
- Seersesjoner som ligger innenfor tidsrommet for samsendingen tildeles én av de involverte kanalene etter en sannsynlighetsfordeling basert på det historiske styrkeforholdet mellom de involverte kanalene på den konkrete skjermen de siste 28 dager.
Prioritet mellom identifikasjonsteknikkene
Dersom rådata fra PeopleMeter er inkonsistente med hensyn til identifikasjon av Innholdet fra Audio Matchingen og Audio Watermarkingen vil Watermarkingen gis prioritet fremfor matching. Dersom det registreres online konsum tracket i censusdata på enheter tilkoblet TV-skjermen, vil dette bli rapportert dersom TV-apparatet står på og det ikke er identifisert broadcast TV-seing samtidig på PeopleMeteret. Dersom det registreres flere samtidige strømmer på flere tilkoblete enheter til en TV-skjerm, rapporteres den strømmen som startet sist. Tidligere startede strømmer tildeles et sluttidspunkt basert på tidspunktet for start av en ny strøm.
Udekket seing
Udekket seing oppstår i tilfeller hvor TV-skjermen står på og ingen har registrert seg som seere. Data fra PeopleMeteret blir underlagt parameterstyrte editeringsregler knyttet til slik udekket seing. Disse vil tildele korte perioder av udekket seing til et Panelmedlem basert på gitte spesifikasjoner. Ved høy grad av udekket seing vil Panelhusstanden bli ekskludert fra det rapporterende Panelet.
4.4.2 Editering av online data
AtriaPro vil prosessere, editere og rapportere online data fra censusmålingen på sekundnivå. Dette gjelder både lineært og on demand innhold hvor både start- og sluttidspunkt for hver streamingsesjon/sendeelement registreres på sekundnivå.
Online innhold som er tagget som \live blir rapportert som lineært innhold i henhold til det kanalnavnet som er angitt i måletaggen.
Lineært online konsum som identifiseres som minst 120 sekunder tidsforsinket gjennom offsetindikatoren i måletaggen blir rapportert som playback. Lineær seing som er inntil 120 sekunder tidsforsinket rapporteres som live.
Online innhold som er tagget som \odm blir rapportert som on demand i henhold til den ContentID som er plassert i måletaggen.
AtriaPro allokerer data til korrekt device i husstanden basert på Mac-adressen. Videre blir sendeelementene tilskrevet personer i panelhusstandene som beskrevet under avsnitt 4.3.
Ved seing på enheter tilkoblet en TV-skjerm vil dette bli rapportert dersom TV-apparatet står på og det ikke er identifisert broadcast TV-seing samtidig på PeopleMeteret. Dersom det registreres flere samtidige strømmer på flere tilkoblete enheter til en TV-skjerm, rapporteres den strømmen som startet sist. Tidligere startede strømmer tildeles et sluttidspunkt basert på tidspunktet for start av en ny strøm.
Rapportering av oppholdssted for onlinedata tracket i census er basert på kobling med data fra FocalMeteret. Konsum som også er registrert av FocalMeteret blir rapportert som "in home" mens konsum som ikke er registrert av FocalMeteret rapporteres som "Out of home".
4.4.3 Editering og validering av data fra RateOnAir
Etter komplett datainnsamling går data fra RateOnAir gjennom en pre-prosessering i Médiamétries software Osmium. Her kombineres seerdata, motiondata og data om oppholdssted og det genereres en seerfil som er klar for videre prosessering i AtriaPro.
Tildeling av minutt
Den kanalen som har majoriteten av minuttet tildeles hele minuttet. Ved likt antall sekunder vil den kanalen som ligger først bli tildelt minuttet.
Smoothing og bridging edit
Smoothing og bridging edit er algoritmer som jevner ut fragmenterte seersesjoner i audience-data i tilfeller hvor en seersesjon brytes i korte perioder med ingen watermark eller watermarks fra en annen kanal.
Tidsforsinket seing for RateOnAir
Ved å sammenlikne tidsstemplet i det registrerte watermarket med tidsstemplet for seertilfellet fastsettes om seingen skal rapporteres som live eller playback. Hvis tidsstemplet for seertilfellet er minst 120 sekunder senere enn tidsstemplet i koden, registreres seertilfellet som playback. Ved avvik inntil 120 sekunder rapporteres seertilfellet som live.
Rapportering av oppholdssted
Alle seerdata fra RateOnAir rapporteres med informasjon om seingen foregikk i eller utenfor hjemmet. Dette fastsettes på grunnlag av informasjon om hvert enkelt RateOnAir kommuniserer med ett eller flere av de beacons som er plassert i husstanden. Kontakt mellom enhetene blir registrert i data hvert 15. minutt. For å redusere forekomster av tilfeldige utfall av kontakt med beacons, blir opphold utenfor hjemmet på inntil 32 minutter editert og regnet som innenfor hjemmet.
Validering av panelmedlemmer
Panelmedlemmer i alderen 18-79 år må ha minst 8 timer motion på sitt RateOnAir for å kvalifisere til rapporterende sample en gitt dag. Personer 10-17 år må ha minst 5 timer motion for å inngå i rapporterende sample. I tillegg inkluderes panelmedlemmer som har oppgitt å være i utlandet i samplet som nullseere.
4.5 Vekterutiner
Panelene vektes på daglig basis ved hjelp av randvekting. Dette innebærer at panelene justeres slik at den vektede fordelingen blir konsistent med universets marginalfordelinger på alle vektevariablene. Det er også mulig å benytte vektevariabler basert på kombinasjoner av flere variabler i en randvektemodell. De daglige vektene fastsettes gjennom en serie iterasjoner som justerer Panelmedlemmenes vekter i henhold til universverdiene inntil summen av vekter innenfor hver vektekategori ligger innenfor et nærmere definert konvergenskrav.
Vektemodellen for de to panelene fastsettes i samråd med oppdragsgiver med utgangspunkt i panelkontrollanalyser basert på Etableringsundersøkelsen. Nivået på vektene rapporteres til oppdragsgiver som en del av Kvalitetskontrollrapporteringen.
Oversikt over vektemodeller og universverdier finnes på siden Universe values.
4.6 Fusjon av de to panelene
Etter at data fra de to panelene er prosessert og vektet som beskrevet over, blir data integrert gjennom en fusjonsprosess. Samplet for det rapporterende panelet i TVOV-undersøkelsen består utelukkende av panelmedlemmer fra Panel A, som blir vektet til å representere TVOV-universet. Panel B bidrar med seing utenfor hjemmet fusjonert inn i Panel A. Barn i alderen 2-9 år fra Panel A rapporteres som en del av det integrerte Panelet uten fusjon av data fra Panel B.
Fusjon er en prosess som finner beste match mellom panelmedlemmer i de to panelene slik at seerdata kan tilskrives fra panel B til panel A med minst mulig feilmargin. Panelmedlemmer i panel B er donorer, mens panelmedlemmer i panel A er mottakere i fusjonen. Beste match kalkuleres ut fra en distance score som sammenlikner hvert mulige par av donorer og mottakere i forhold til en rekke kjennetegn kalt fusion hooks. Modellen er satt opp med 14 kritiske segmenter basert på kjønn og alder i 10-årskutt. Det betyr at det kreves absolutt match mellom donor og mottaker innenfor disse målgruppene. Videre er det definert en rekke andre hooks, basert på demografiske kjennetegn og seertidsvariabler basert på in home TV-seing siste 28 dager i begge panel. Det benyttes seertidsvariabler både på totalnivå, per kanalgruppe, per day part og per sjanger.
For hver fusion hook er det fastsatt en weight som angir hvor viktig det er at donor og mottaker skal være så like som mulig på den relevante variabelen. Variabler med stor betydning tildeles høy vekt slik at ulikhet på variabelen medfører en høy distance score og dermed redusert sannsynlighet for match. Vektene kan settes til ulike nivå innenfor hver av de 14 segmentene, basert på hvilke faktorer som har størst betydning for seing utenfor hjemmet innenfor hver målgruppe. Fusjonsmodellen vil på denne måten etablere en best mulig match mellom donor og mottaker basert på både demografiske kjennetegn og dynamiske atferdsvariabler.
Fusjonsmodellen tillater at hver donor kan benyttes flere ganger, men det blir benyttet penalties for å unngå overbruk av enkelte donorer. Målsettingen er å gjøre mest mulig jevn bruk av tilgjengelige donorer innenfor de kritiske segmentene. Videre er det slik at den beste donoren ikke nødvendigvis er den donor med lavest distance score. Det benyttes en algoritme som matcher donorer og mottakere basert på en samlet vurdering av tilgjengelige donorer. Enkelte typer donorer kan være sjeldne og bør derfor benyttes der de trengs mest, og ikke på mottakere som har andre potensielle donorer som er nesten like gode.
Modellen benytter dessuten en mekanisme kalt inheritance, som innebærer at valgt donor fra siste dagers fusjon vil ha økt sannsynlighet for å bli valgt igjen, gitt at den fortsatt vurderes som en god match. Formålet er å redusere risikoen for kunstig økning av rapportert dekningsnivå over tid. Denne fusjonseffekten kan oppstå dersom hver enkelt donor tildeler sin seing til et stort antall mottakere over tid. For å motvirke dette blir tidligere tvillingpar gitt en fordel i fusjonen ved at alle andre donorer gis en inheritance penalty.
Etter at fusjonsmodellen har funnet beste match mellom panelmedlemmer fra de to panelene, blir broadcast seing utenfor hjemmet på definerte kanaler lagt over fra donor i Panel B til mottaker i Panel A.
Ved overføring av data fra Panel B til Panel A vil det kunne oppstå tilfeller hvor man legger over seertilfeller som helt eller delvis sammenfaller i tid med eksisterende seertilfeller hos mottaker. Slik overlappende seing tillates, men modellen inneholder algoritmer for bytte av seertilfeller mellom mottakere i Panel A slik at overlappende seing hjemme og utenfor hjemmet på samme kanal unngås.
4.7 Harmonisering av paneldata med Censusdata
De målte seertallene for online konsum fra panelet blir hver dag harmonisert med censusdata fra TV-selskapenes trafikkmålinger. Censusdata gir eksakt informasjon om totalt avspilte minutter for hvert enkelt sendeelement (contentID og spotID) og totalt. Censusdata gir også en fordeling av konsumet på type skjerm. Censusdataene gir likevel ikke den fulle sannheten over hvor mange personer som har sett et gitt innhold. Her bidrar panelet med informasjon om hvilke personer og målgrupper som står bak online konsumet. Panelet gir også tall for samseing samt dekning på tvers av plattformer.
Ved å kombinere disse datakildene blir de rapporterte paneldataene kalibrert til å stemme overens med fastsatte targets. Det settes targets for både redaksjonelt og kommersielt innhold (contentID og spotID). Dersom målte paneldata ligger høyere enn fastsatte targets, blir det fjernet seertilfeller fra panelet. Dersom målte paneldata ligger lavere enn fastsatte targets, blir det lagt til seertilfeller i panelet inntil samsvar er oppnådd for den aktuelle målgruppen eller skjermtypen. Harmoniseringen med censusdata skjer for de meste sette innholdselementene enkeltvis, mens resten av konsumet harmoniseres på totalnivå for hvert TV-selskap. For en nærmere beskrivelse av censusdata se Censusdata - begrepsavklaring.
TVOV-undersøkelsen er satt opp med to separate harmoniseringsprosesser, en for redaksjonelt innhold og en for kommersielt innhold. Disse prosessene kjøres parallelt, men samles til slutt i ett samordnet datasett. Modellene er satt opp med innhold og nedbrytinger som angitt i tabellen under:
| Harmonisering av program | Harmonisering av kommersielt innhold | |
|---|---|---|
| Broadcastere | NRK, TV 2, og Discovery Networks | TV 2, og Discovery Networks. |
| Live/On demand | On demand og Live (kun TV 2 sine kanaler) | On demand og Live (kun TV 2 sine kanaler) |
| Toppliste for særskilt harmonisering | NRK: 750 mest sette program TV2: 1000 mest sette program Discovery: 250 mest sette program (minimum 10 sekunders duration og minst 5000 minutter konsum i census per contentid) | 280 mest sette spoter totalt (minst 2 sekunders duration og minst 1000 minutter konsum i census per spotid) |
| Event types | Program og promo | Spoter og sponsorat |
| Demografier | 13 grupper: kjønn x alder i 10-årskutt | 13 grupper: kjønn x alder i 10-årskutt |
| Device typer | TV, other | TV, other |
Data input i harmoniseringen
I tillegg til datafiler med dagens onlineseing fra panelet, inngår følgende data og informasjon for gjennomføring av kalibreringen:
- Census Targets: Disse dataene hentes fra broadcasternes trafikkmålinger og inneholder informasjon om totalt avspilte sekunder per ContentID eller SpotID per devicetype.
- Metadata per ContentID: For at et innholdselement skal kunne inngå i harmoniseringen forutsettes tilgjengelige metadata per ContentID eller SpotID. Som et minimum kreves informasjon om duration, event type og sjanger (for program) eller produktkategori (for spoter).
- Historiske paneldata: Algoritmene benytter søkerutiner i historiske paneldata i 28 dager bakover i tid. Dette benyttes for å bygge demografiprofiler, beregne samseing samt modellere dekning.
- Uttrekk fra Censusdata: I selve kalibreringen av paneldata til å matche de fastsatte targets, benyttes faktiske seersesjoner fra Censusdata som transporteres over til panelet. Det benyttes et tilfeldig uttrekk på 20 prosent av seersesjoner (endret fra statements til sesjoner 27.09.2023) fra Censusdata til dette formålet.
Fastsettelse av targets
Første fase i harmoniseringsprosessen består i å fastsette targets, dvs. nivåene paneldata blir kalibrert til i siste fase.
Program: For hver broadcaster fastsettes separate targets for hver av de mest sette programmene, som deretter brytes ned på 13 demografier og to devicetyper. Det settes separate targets på serienivå (Series ID). I tillegg fastsettes targets for de øvrige innholdselementene under ett, og for totalnivå per broadcaster. Det fastsettes targets både for konsum og for dekning. Se 4.8 for oversikt over nedbrytningen av targets.
Reklame: For det kommersielle innholdet (spoter) fastsettes targets på tvers av broadcastere. Det fastsettes separate targets for hver av de mest sette spotene, som deretter brytes ned på 13 demografier og to devicetyper. Det settes separate targets for kampanjer (Sub Brand ID). I tillegg fastsettes targets for de øvrige innholdselementene under ett, på tvers av broadcastere. Se 4.9 for oversikt over nedbrytningen av targets.
Targets for konsum beregnes ved å ta utgangspunkt i censusdata fra trafikkmålingene, som viser totalt avspilte sekunder per ContentID og SpotID per devicetype. Disse dataene kombineres så med data om samseing fra panelet slik at konsumtargets som regel er høyere enn de rene censusdataene.
I tillegg til å fastsette targets for konsum, modelleres targets for dekning for de mest sette programmene/spotene og de andre rapporteringskategoriene i modellen. Det fastsettes targets for både 1, 7 og 31 dagers dekning. Modellen tar utgangspunkt i paneldata for å estimere en dekningskurve som representerer forholdet mellom minutter og dekning. Om nødvendig vil referansedata utvides med paneldata for lignende TV-innhold inntil tilstrekkelig sample er funnet for å estimere dekningskurven. Ved å anvende denne formelen på census minutter inkludert samseing, skaleres dekningstarget til census konsum.
Den tredje formen for targets som beregnes i første fase av harmoniseringsmodellen er cross platform targets (CPR). Disse uttrykker andelen seere som har sett et TV-innhold både på broadcast TV og online og modelleres med utgangspunkt i panelobservasjoner. Cross platform targets fastsettes per broadcaster og per program for redaksjonelt og per kampanje og spot for kommersielt over 31 dager.
Ved å koble på metadata med informasjon om varighet på hver ContentID og SpotID, kalkuleres rating per innholdselement for fastsettelse av topplisten over hvilke program/spoter som skal harmoniseres særskilt. Topplisten fastsettes ved en rangering som kombinerer rating (90% vekt) og totalt avspilte sekunder (10% vekt). Det er også definert en minste varighet på elementet for å kvalifisere til topplisten, henholdsvis 10 og 2 sekunder for program og spot. For program forutsettes minst 5000 minutter i targetverdi (censusdata oppjustert med samseing) for at det skal være mulig å harmonisere særskilt, mens for spoter kreves 1000 minutter. Elementer med lavere targetverdi havner i restkategorien per broadcaster for program og i en felles restkategori på tvers av broadcastere for reklame.
For å fastsette hvordan konsumet på et gitt innholdselement skal fordeles på de 13 demografiene og de to devicetypene, benyttes paneldata. For store programmer/spoter vil det være nok seere i panelet til å bygge en demografisk profil direkte. Modellen krever et minimum sample (195 for program og 130 for spoter) for å fordele konsumet på de 13 målgruppene og de to devicetypene. Dersom det ikke er stort nok sample på det aktuelle programmet eller reklamespoten, vil modellen utvide datagrunnlaget bakover i tid med tidligere seere på samme program/reklame og eventuelt også lignende innhold, inntil et tilstrekkelig utvalg er nådd. Disse algoritmene gjør det også mulig å rapportere kalibrerte seerdata for innhold og reklame som ikke har noen seere i panelet en gitt dag. Algoritmene gjør bruk av sjangerklassifiseringen for program og produktkategori for reklamespoter for å utvide datagrunnlaget for å finne demografiprofiler.
Virtual panel expansion
Det integrerte datasettet er basert på et rapporterende sample av ca 3300 personer i alderen 2-79 år. Disse representerer hele befolkningen i alderen 2-79 år, som i dag utgjør et univers på 5 075 000 personer. Dette betyr at hvert panelmedlem i snitt representerer ca 1500 personer i befolkningen.
Som en del av harmoniseringen med censusdata blir det gjennomført en virtual panel expansion. Dette er en teknisk øvelse med formål å øke granulariteten av data, slik at innholdselementer med lavt konsum kan rapporteres mer presist. I praksis innebærer dette at det lages (gjennomsnittlig) 15 kopier av hvert panelmedlem samtidig som vekten til hver kopi settes til 1/15 av opprinnelig vekt. Videre blir det laget 15 kopier av de opprinnelige seertilfellene slik at de aggregerte seertallene er uendret etter ekspansjonen. Som et resultat av dette representerer hvert virtuelle panelmedlem gjennomsnittlig kun 100 personer i universet. Det betyr også at TVOV datasettet består av nærmere 50 000 virtuelle panelmedlemmer.
Denne virtuelle utvidelsen av panelet er en viktig forutsetning for å kunne gjennomføre harmonisering av paneldata med censusdata. Når hvert virtuelle panelmedlem representerer så liten del av universet gir det økt mulighet for å rapportere presise seertall med sikre demografiprofiler for innholdselementer med lavt konsum.
Kalibrering av Paneldata til fastsatte targets
Siste fase av harmoniseringen går ut på å kalibrere de opprinnelige paneldataene inntil de oppnår så godt samsvar som mulig med de targets som ble fastsatt i første fase - for det enkelte innholdselement, målgruppe og device type.
Først sammenliknes opprinnelige paneldata med fastsatte targets for alle nedbrytinger. Så kalkuleres avviksmatriser som angir hvor mange sekunder konsum og hvor mye dekning som må legges til eller fjernes for å oppnå samsvar mellom paneldata og targets. Noen targets vil ha for lite konsum i panelet, mens andre vil ha for mye.
Basert på dette blir det deretter lagt til eller fjernet konkrete seersesjoner på (virtuelle) panelmedlemmer inntil samsvar er oppnådd for alle targets, både når det gjelder konsum og dekning. I dette steget gjøres vurderinger av dekningsnivå i utvelgelsen av hvilke panelmedlemmer som skal tildeles eller fratas seing. Dersom det skal legges til konsum på et program eller en reklame, vurderes hvorvidt konsumet skal gis til et panelmedlem som også medfører økt dekning på innholdselementet, på kanalen, per dag og per uke. Dersom et innholdselement skal ha økt konsum uten at det ukentlige dekningsnivået skal økes, vil modellen tildele seertilfeller til panelmedlemmer som allerede er seere av innholdselementet.
For targets hvor det skal legges til økt konsum i panelet, skjer dette ved å trekke tilfeldig faktiske sesjoner fra Censusdataene. Formålet med å bruke faktiske Censusdata og trekke tilfeldig fra disse er å gjenskape den reelle seerflyten fra Censusdata. Tilfeldige uttrekk av seertilfeller vil bidra til at seerutviklingen gjennom døgnet samsvarer med Census. For innholdselementer som ikke kalibreres særskilt, vil dessuten Content- og SpotIDer med høyt konsum ha høyere sannsynlighet for å bli trukket ut enn Content- eller SpotID med lavere konsum. Dermed blir rapporterte program og reklamer på restkategorien også godt harmonisert med Censusdata.
Censusdata omfatter konsum på alle oppholdssteder, men inneholder ikke informasjon om hva som konsumeres i og utenfor hjemmet. I de tilfeller hvor harmoniseringen legger til seertilfeller i panelet, blir dette rapportert på siste kjente oppholdssted for det virtuelle panelmedlemmet.
Censusuttrekk
Kantar mottar daglig et uttrekk av 20% disaggregerte censusdata som benyttes i allokeringen av seertilfeller i kalibreringen. Uttrekket er tilfeldig og det trekkes 20% av sesjoner, som også vil tilsvare omtrent 20% av konsumet, og dette vil i stor grad gjenspeile full census når det gjelder tid på døgnet og lengde på seertilfellene.
De mest sette programmene og spotene blir kalibrert individuelt, mens resten av programmene/spotene blir kalibrert samlet (rest bucket) for å sikre korrekt representasjon av totalnivå. Innholdselementer vil kun tildeles seertilfeller fra census tilhørende egen contentid. Altså, census-seertilfeller fra ett innholdselement (contentid/spotid) vil ikke kunne legges til et annet innholdselement. I kalibreringen av «rest bucket» vil program/spoter med høyt konsum ha større sannsynlighet for å bli allokert enn program/spoter med lavt konsum.
Kalibrerte Audience data etter harmoniseringen
Resultatet av harmoniseringen er et endelig datasett med kalibrerte paneldata i et åpent filformat som kan lastes til Analysesoftware. Paneldata blir rapportert i form av en personfil med (virtuelle) panelmedlemmer med vekter og demografiopplysninger. Videre rapporteres audiencefiler med alle broadcast og online seertilfeller, både lineære, tidsforsinket og On demand, for hvert enkelt (virtuelle) panelmedlem.
4.8 Trehierarki kalibrering av redaksjonelt innhold
Gjeldende fra 3. april 2020
Viser nedbrytningen av targets for program. For detaljer se 4.7 Fastsettelse av targets.
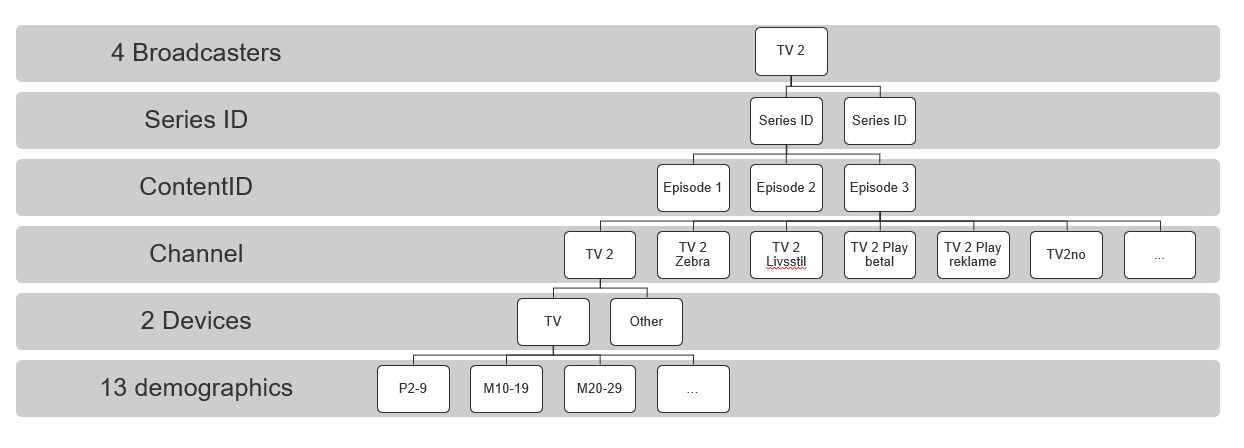
Series ble lagt til fom. 19. mars 2021.
Lineære kanaler ble lagt til for TV 2 fom. 10 September 2021
4.9 Trehierarki kalibrering av kommersielt innhold
Gjeldende fra 28. august 2020.
Viser nedbrytingen av targets for kommersielt innhold. For detaljer se 4.7 Fastsettelse av targets.
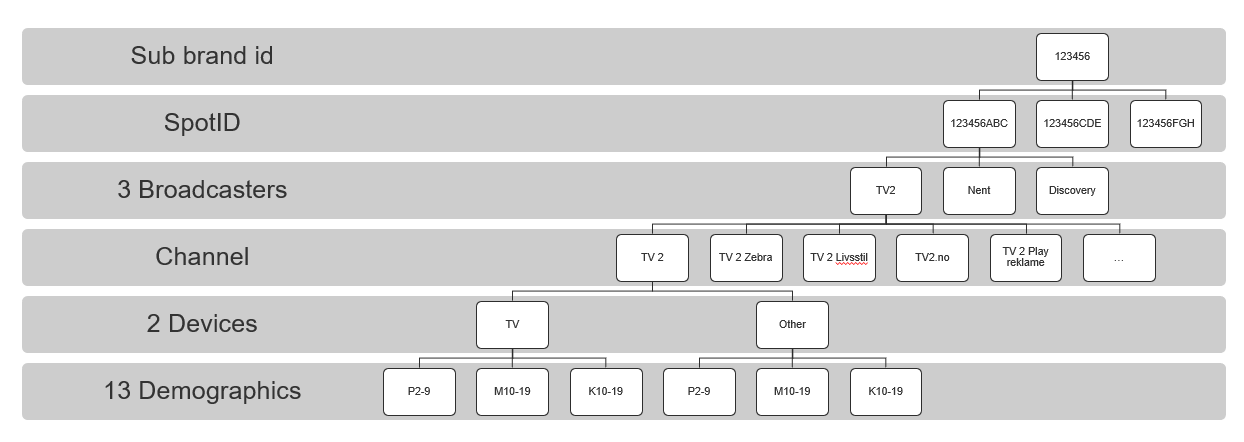
Lineære kanaler ble lagt til for TV 2 fom. 10 September 2021
4.10 Produksjon og tilkobling av Metadata
Som et siste element i prosesseringen av Data ligger påkobling av Metadata. Dette består av logger for de lineære kanalene samt metadata for on demand elementene som beskriver og dokumenterer innholdet i audiencefilene fra det integrerte panelet. Det vises til kapittel 5 for en nærmere beskrivelse av denne prosessen.
4.11 Datasikkerhet
Kantar følger en rekke sikkerhetsrutiner:
- Dobbelt sett med systemer for datainnsamling for alle måleteknologier.
- Dobbelt sett av alle referansedata som lages.
- Maskiner involvert i innsamling og prosessering av Data er tilknyttet nødstrømsanlegg, og står i brannsikrete, avlåste lokaler, der kun autorisert personale har adgang.
- Maskiner på hoved- eller backuplokasjon står bak Kantars brannvegg som forhindrer tilgang utenfra.
- Samtlige maskiner er passordbeskyttet og sensitiv informasjon er kryptert og tilgangsgradert.
- Kryptert dataoverføring.
- Bruk av monitoreringsverktøyet Nagios.
- Det blir tatt daglige sikkerhetskopier av vitale data som lagres på en annen geografisk lokasjon.
- 24-timers serviceavtaler med produsenter av utstyr og programvare.
Som en del av Kantar Media følges Kantar Medias retningslinjer når det gjelder datasikkerhet definert under såkalte Project Shield. Som en del av WPP-konsernet er vi også underlagt Sox IT-direktivet. Sox IT er et omfattende kontroll- og rapporteringssystem for å sikre bedriftens datasystemer. Kantar Norge rapporterer alle 20 Sox IT- kontrollområder, herunder innbruddssikring, brukerkontroll, sikkerhetskopier og krisehåndtering. Kantar Media følger de lover, retningslinjer og bransjestandarder som gjelder vår virksomhet for å ivareta konfidensialitet, anonymitet og personlige opplysninger. Dette innbefatter blant annet den nye GDPR-loven og Datatilsynets retningslinjer. Våre rutiner, systemer og framgangsmåter er i tråd med bransjens ISO standard og etiske retningslinjer.