Internet Audience Measurement
| Status | Working Document |
|---|---|
| Author | Ralf Cornehl (KASRL) (Unlicensed) |
| Date | 10.05.2021 |
| Version | 1.6 |
Version | Date | Author | Comments |
|---|---|---|---|
1.0 | 21.02.2018 | Initial | |
| 1.1 | 12.04.2019 | Ralf Cornehl (KASRL) (Unlicensed) | Update Geo-location Attribution |
1.2 | 21.05.2019 | Device Type Recognition | |
| 1.3 | 18.01.2020 | Ralf Cornehl (KASRL) (Unlicensed) | FAQ added |
| 1.4 | 26.10.2020 | Ralf Cornehl (KASRL) (Unlicensed) | SDK Development |
| 1.5 | 07.12.2020 | Ralf Cornehl (KASRL) (Unlicensed) | IP-Address handling Cookie handling |
| 1.6 | 10.05.2021 | Ralf Cornehl (KASRL) (Unlicensed) | Kantar Browser Meter |
Content
The site centric and user centric measurement system we propose is based on our proven Kantar - Media Division solution and features:
- Site Centric Measurement (IAM-Sensor)
- Mobile/Tablet Site Centric Measurement (Mobile-Web-Sensor)
- Mobile/Tablet App Measurement (Mobile-App-Sensor)
- Web-Player Streaming Measurement (Desktop-Player-Sensor)
- Mobile/Tablet Streaming App Measurement (Mobile-App-Player-Sensor)
- Special Platform Streaming Measurement (Special Platform-Player-Sensor)
- User Centric Measurement
- Hybrid Measurement
IAM-SDK
Desktop-Web-SDK
Data acquisition of the site centric measurement system is facilitated by a state of the art script-tag that allows to track users on ALL devices
(including mobile devices like iPad/iPhone) beyond the lifetime of their browser-cookies and is still compliant to ECC privacy guidelines.
The Tag is delivered as a java script package that is easily integrated into the web content.
Client specific dimensions and variables can be defined (like content areas).
<html>
<head>
</head>
<body>
<script src="spring.js">
</script>
<script language="Javascript">
var sp_e0 = {
"s":"testsite",
"cp":"Path/to/your/page",
"url": document.location.href
};
spring.c(sp_e0);
</script>
</body>
</html>
The Tag can be used either synchronous or asynchronous. Asynchronous loading prevents page-loading to be delayed but does register fewer Pageviews.
Mobile-Web-SDK
The sensor to facilitate the measurement of mobile browser usage is made up as a “cascade” of technologies to allow for the most accurate (re)-identification
of users visiting mobile enabled websites even on non-cooperative devices. The system uses a combination of technologies for this.
The sensor is being deployed to websites as a Javascript-Package.
Mobile-App-SDK
The sensor for measuring mobile applications consists of a number of SDKs to be integrated into the mobile applications of participating publishers.
Currently the system extensively supports iOS and Android applications. The libraries are able to track the life cycle events of a mobile application
like "started", "foreground", "background" and "closed".
Additionally, Internet content rendered into a "Webview" of the mobile application can be tagged and subsequently be reported.
To be compliant with European standards in terms of data protection and privacy, the libraries also offer an opt-out option that can be easily triggered from the applications.
Integration
The integration is typically done in less than a work day.
VAM-SDK
The Streaming measurement system we propose is based on our proven Kantar - Media Division solution and features an easily integrable in-player SDK for all modern players
It gives accurate measurement and reporting of the streaming usage (Audio or Video) on Live or recorded or downloaded content (Offline Mode).
Data-Flow of Data Acquisition - System Schematics: (Web-Video-Player)
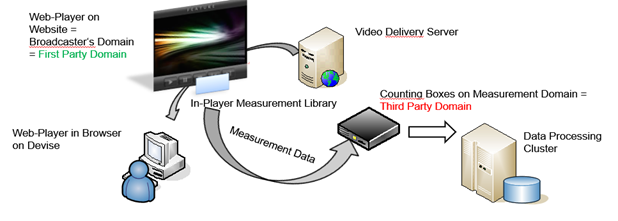
The measurement SDK can be integrated with ANY player and the measurement system supports the following technologies:
Desktop-Player-SDK
- HTML 5
- Flash (unsupported since end of 2020)
- Flash Action Script 3 (unsupported since end of 2020)
- Flash OSMF (unsupported since end of 2020)
- Brightcove
- Silverlight
Mobile-App-Player-SDK
- iOS
- Android
Special Platform-Player-SDK
- Apple TV (TVJS/TVML)
- Apple TV (tvOS)
- Chromecast
- Cordova
- Electron
- LibJscript
- Playstation 3 and 4
- Roku
- TAL (SmartTV)
- Xbox
- Other technologies (like proprietary players) can be integrated via a generic JS interface (adapter)
Special SDK or Plugin Development
On special occasions Kantar can develop and provide a standalone measurement SDK or special plugin in cooperation with broadcasters when their current video player framework
is not covered by the above-mentioned standard SDKs and thus needs a separated treatment on software development and implementation.
Integration
The integration is typically done in less than a work day.
SDK Development
Kantar’s software development for SDKs is being operated on an “agile” software development approach using a Scrum method [https://en.wikipedia.org/wiki/Scrum_(software_development)].
The development sprint intervals are regularly set to a 3-weeks cycle. For covering special development needs (e.g. initial development for platform support)
development sprints can be extended up to 4 weeks, thus keeping the highest flexibility for possible development iterations and achieving constant developer feedback loops.
Respecting the availability of development resources on sprint planning and integration of a development buffer allows for timely “ad-hoc”-handling of urgent SDK issues surfacing during running development sprints.
SDK Testing (QA)
The Kantar QA process for SDK products is integrated into the overall agile development cycle. For all our products, Kantar maintains sets of regression scenarios, which are the basis for any release test.
These sets will be extended, respectively adjusted, if new features or changes in current business logic appear in the latest development iteration.
As for the Kantar QA workflow, the QA department will receive a feature complete SDK artifact (RC = release candidate) from the implementing team
together with a brief description of any new features or adjustments, once the initial implementation of all requirements has been reached.
The QA department then will adopt any updates into their set of regression scenarios.
Based on these scenarios and the received RC the integration test will be performed and documented.
If the RC meets all requirements, it will be declared by QA team as accepted, which subsequently triggers the build of the final release artifact (SDK production release) which is identical to the latest RC.
If any findings or defects appear during testing of a RC, the corresponding SDK artifact will be declared as rejected and the development team will be informed about the findings or defects.
In this case, the development team needs to adjust the current SDK artifact in regard to the finding and build a new RC which then again will be sent to the QA department for testing purposes.
This interaction between the QA department and the corresponding development team is cyclic, until a RC is declared as accepted.
Technology-wise, we divide QA into internal and integration testing.
Internal tests cover internal details of a SDK product – granular components, such as algorithms, classes or functions.
These tests are implemented as unit tests, using the unit testing framework of the corresponding programming language.
As a result, they are fully automated and integrated into our build pipelines, which ensures, that every software artifact produced by a development team is fitting these tests.
Integration tests cover cases, in which the whole software artifact is integrated into the environment, in which it will be running in production.
This covers any interaction with the environment, e.g. the operation system, as well as complex orchestration of various sub-components or algorithms.
Kantar relies heavily on automation in this area as well, in order to ensure consistency. For front-end products Kantar uses state of the art automation frameworks
like Selenium (https://www.selenium.dev/) and Appium (http://appium.io/) to implement the automation of these tests. To cover as many platforms as possible during these tests,
we are using the cloud service Saucelabs (https://saucelabs.com), which provides the possibility to access a wide range of real devices as well as device simulations through the cloud.
Kantar also enabled a more abstract layer on top of that which encapsulated the technical details and provides human readable specification of an integration scenario.
This behaviour driven attempt reduces the barriers in communication between market stakeholders and the Kantar QA team and ensures,
that integration testing provides valuable information on how the product will behave in a customer scenario.
For the processing product, Kantar will using for 2021 the Azure big data technologies and the Azure test procedure they are implemented.
Kantar also enabled a more abstract layer on top of that which encapsulated the technical details and provides human readable specification of an integration scenario.
This behaviour driven attempt reduces the barriers in communication between market stakeholders and the Kantar QA team and ensures,
that integration testing provides valuable information on how the product will behave in a customer scenario.
SDK Maintenance
Kantar is constantly and regularly performing reviews on browser and operating system (OS) vendors in determining changes to happen upon introducing new releases for them.
Impact assessment of those vendor announcements on Kantar SDKs and/or broadcaster feedback on SDKs given via Kantar’s own service desk will lead to development inputs
for Scrum sprint planning in building up work packages for initial software development and/or bug fixing by simultaneously respecting Kantar’s available development resources.
SDK Release Cycles
In following up the main technology vendors like Apple for iOS, Google for Android and additional constant review on browser vendors
and video player frameworks Kantar observes upcoming release cycles given for the respective platform.
Major updates and/or upgrades on them are adopted for Kantar’s SDK release cycle planning.
Most common time patterns for individual platforms have been established by vendors over the course of the past years.
Google is releasing new major versions of Android mostly during summertime (July/August).
Apple is doing so for iOS by announcing and introducing new smartphone or tablet models in late summer or autumn (August/September).
For covering the major releases of those vendors Kantar is planning major SDK releases within the same time frames as well.
Internal code reviews and broadcaster feedback on SDKs may lead to bugfix or hotfix scenarios which are being provided in form of intermediate minor releases on an ad-hoc basis.
FAQ
How does a tracking request look like?
The Kantar Media Division requests are HTTP-GET-requests. They contain all the information required for measurement.
Example for a website measurement request:
GET 302 Redirect to: /blank.gif http://test.tns-cs.net/j0=,,,r=https%3A%2F%2Fwww.google.com;+,cp=test+url=www.test.com;;;?lt=ig36v70v&x=1600x900x24 GET 200 image/gif http://test.tns-cs.net/blank.gif
See the explanation of the request elements in the below table.
| Element of the request | Description |
|---|---|
http://test.tns-cs.net | call to counting domain |
r=https%3A%2F%2Fwww.google.com | r-variable = referrer |
cp=test | cp-variable = content path set to unify content |
url=www.test.com | url-variable = URL where the content is placed |
lt=ig36v70v | lt-variable = random parameter to avoid browser-caching |
x=1600x900x24 | x-variable = screen resolution |
Example for a video measurement request
Heartbeats sent from the SDK
This section briefly explains what the heartbeats sent from the libraries should look like. A concrete example of a viewing session is used.
Content Stream is started and the first Request transmitted
Please use the record layout descriptions below for reference.
First Request Statement
The actual record output should look similar to below:
First play state: 0+0+mbeswh
http://example.tns-cs.net/j0=,,,pl=jwplayer+plv=version1+sx=640+sy=517;+,stream=od+cq=123456789+uid=3f3tv5p+pst=,,0+0+mbeswh;+,1+1+mbeswj;;+dur=1501+vt=2;;;
Please use the record layout descriptions below for reference.
| Variable | Description |
|---|---|
| counting domain | "tns-cs.net" = Norwegian counting domain e.g. “sitename” = “example" for a site |
| pl | player = own player name (set by the broadcaster) |
| plv | player version = own player version (set by the broadcaster) |
| sx | width of the stream window |
| sy | height of the stream window |
| stream | stream name (set by the broadcaster) |
| cq | content-ID = broadcaster's content ID (set by the broadcaster) |
| uid | unique Id of the view sequence |
| pst | play state = list of viewing intervals on the stream |
| dur | stream length in seconds (set by the broadcaster) |
| vt | view time in seconds (time of visual contact with the stream) |
After Viewing 2 min of the Stream
The output records should look similar to the records below, note the time of the “heartbeat” records = play states records at 21, 41, 61,.... seconds
http://example.tns-cs.net/j0=,,,pl=jwplayer+plv=version1+sx=640+sy=517;+,stream=od+cq=123456789+uid=3f3tv5p+pst=,,0+0+mbeswh;+,1+21+mbeswj;;+dur=1501+vt=22;;; http://example.tns-cs.net/j0=,,,pl=jwplayer+plv=version1+sx=640+sy=517;+,stream=od+cq=123456789+uid=3f3tv5p+pst=,,0+0+mbeswh;+,1+41+mbeswj;;+dur=1501+vt=42;;; http://example.tns-cs.net/j0=,,,pl=jwplayer+plv=version1+sx=640+sy=517;+,stream=od+cq=123456789+uid=3f3tv5p+pst=,,0+0+mbeswh;+,1+61+mbeswj;;+dur=1501+vt=62;;; http://example.tns-cs.net/j0=,,,pl=jwplayer+plv=version1+sx=640+sy=517;+,stream=od+cq=123456789+uid=3f3tv5p+pst=,,0+0+mbeswh;+,1+83+mbeswj;;+dur=1501+vt=84;;; http://example.tns-cs.net/j0=,,,pl=jwplayer+plv=version1+sx=640+sy=517;+,stream=od+cq=123456789+uid=3f3tv5p+pst=,,0+0+mbeswh;+,1+105+mbeswj;;+dur=1501+vt=106;;;
Stopping the Stream after 2:00 min
Last play state: 1+121+mbeswj = 120 sec playtime.
http://example.tns-cs.net/j0=,,,pl=jwplayer+plv=version1+sx=640+sy=517;+,stream=od+uid=3f3tv5p+pst=,,0+0+mbeswh;+,1+121+mbeswj;;+dur=1501+vt=124;;;
- Note that the "uid" (uid=3f3tv5p) and stream name "stream" (stream=od) remained the same during the whole view sequence.
This should always be the case when the implementation is correct. - If the "uid" or "stream" (=stream name) changes during the observed view sequence, there is something wrong with the implementation
and as a consequence more than one stream view is being counted for this single view sequence. - The above example is a generic one.
- For the streaming project by continuously viewing a stream you should be seeing heartbeats sent out at 0,1,20,40,60,80,100,120,.. seconds.
There may be 1 or 2 seconds added to every heartbeat due to internal workings of the library.
How can I control those requests?
Step-by-step Instructions for running an HTTP-Request-Analyser:
Why is a 302 redirect used?
When a request hits our servers, it is measured and then answered back with a http-302-redirect response (“temporarily moved”).
This 302-redirect forces caching mechanisms such as proxies or browser-cache, to request the resource anew from the server.
However, the related RFC2616 is not completely implemented here. In replying the redirect-URL to the client, only the URI-part is sent (host name of the server omitted).
This leads to a higher performance of the system and a reduction of the transfer volumes.
For repeated requests, the saving is about 10 bytes per response compared to full responses.
Additionally in the local client, only one copy of the blank.gif is allocated and processed.
How is the IP-Address used?
Kantar only uses the IP-address in a truncated form (last octet removed) on run-time (for milliseconds) in RAM on our measurement boxes and after that they are discarded.
Our measurement boxes even don’t have any physical storage capacity for this purpose.
The IP-address is needed to execute the HTTP-traffic operations (= Internet communication) and to allow for geolocation attribution.
To be GDPR compliant they are never getting used afterwards in any of our data processing after measurement nor are they stored elsewhere.
This procedure of IP-address handling has already been audited by local data privacy organizations in Germany when we as formerly being “spring” were still part of the AGOF measurement,
which had now been taken over by a company called INFOnline using our technology approach.
Same approach is also being in production for Switzerland (Netmetrix) and Austria (ÖWA) (and in our current measurement projects across the globe).
All these countries explicitly mentioned above are known for their strict GDPR regulations.
This approach considers already in the measurement context a “privacy by design” model.
How are cookies used?
Data acquisition of the site centric measurement system is facilitated on browsers by a state- of-the-art script-tag that allows to track users on desktop and mobile devices
(including such mobile devices like tablets and smartphones) beyond the lifetime of their browser identifiers and which is still compliant to ECC privacy guidelines.
The “Tag” is delivered as a java script package that is easily to be integrated into the web-player context.
The broadcaster’s content (video or audio) is typically hosted on a specific domain, which is considered as the content domain = “First Party Domain”.
The measurement requests are sent to a different domain, which is considered as the measurement domain = “Third Party Domain” in the broadcaster’s context.
Available browser identifiers are being used to uniquely identify a video viewing sequence (session handling) by the device’s browser.
The i00-HTTP Cookie
The i00 HTTP-cookie content consists of: (in hexadecimal form)
- box-id (first 4 digits)
- time stamp (8 digits)
- counter (4 digits)
(- serial (4 digits) irrelevant for the HTTP-context)
The HTML-5 Local Storage Cookie
The c (HTML5-cookie) is only a parsed cookie through our boxes and set by the java script (16 hexadecimal form)
if(!this.nlso)
try {
var l = localStorage.getItem('i00');
if(l) return '&c='+l;
else {
var ta = '0000',
id = ta + Math.ceil((new Date()).getTime()/1000).toString(16) + (0x8000|Math.random()*0xffff).toString(16) + ta;
localStorage.setItem('i00',id);
}
The difference:
- the i00-cookie is set by the box as active component
- the HTML5-cookie is NOT set by the box (=passive behavior)
For cookie handling and processing see chapter: Client-Resolving
How to define a page view?
A PageImpression/PageView describes the call of one Webpage by the user.
The following requirements have to be met before a PageImpression/PageView can be counted and referred to a special counting-ID:
- The page has to meet the FQDN (https://en.wikipedia.org/wiki/Fully_qualified_domain_name) for the website (or alias/redirect).
- The page has to belong to the site, either in look and feel or by a clear and obvious optical ID.
- Each call of the page may be counted only once.
- The call of the page has to be user-induced.
The following examples describe user-induced actions and substantial changes, which could either be counted or not counted.
User-induced actions: (counted)
- Call of a new page or new parts of the page, caused by mouse click or keyboard entry.
- Call of same page or same parts of the page (reloads), caused by mouse click or keyboard entry.
- Open a browser.
Non user-induced actions: (not counted)
- Call of a new page or new parts of the page by automatic forwarding (beside redirects and alias).
- Call of the same page the same parts of the page by automatic reload (e.g. news ticker).
- The call of a page by closing a window.
- The call via robots/spiders and similar.
Substantial change: (counted)
- Changes of text passages, whose context is in the main focus of the page.
- Changes of visual, multimedia contents, whose context is in the main focus of the page.
- Asking a new question in quiz games/surveys.
- Loading of new picture within a picture gallery (slide-show).
Non substantial change: (not counted)
- Changes of the page by crossing with the mouse (mouse-over)
- Shift of monitor contents by aid of mouse or keyboard
- Entry of single signs, whereas the content change is to represent the input characters
- Selection of monitor contents by aid of mouse or keyboard (e.g. select box)
- Scrolling with mouse or keyboard within one page
- Change of color (text, picture, background etc.)
- Change of layout of the page, without changing the content
Conclusion: User-induced means every action of a user which geared to call a page, in order to cause a substantial change of the site content.
How is the last page view handled?
When a client has more than one activity within a session, the "duration" (page viewtime) of the current activity is assumed to be ended by the next.
So the viewtime is not computable for all activities, because the last activity in a session has no successor in time.
To display figures for all activities in the system, a projection is used:
- the average duration of all measurable activities (i.e. with successors) is computed
- and that average duration is projected to all activities.
Assumption: the missing viewtimes are well represented by the existing ones.
Example:
- a certain webpage has 100 pageviews and a measurable viewtime for 90 pageviews is counted
- for 10 pageviews the vietime is missing
- the system collected 180 seconds for those 90 pageviews
The average viewtime per measurable pageview is them 180/90 seconds = 2 seconds.
Which is - by assumption - the average of all 100 pageviews too.
Conclusion: The total viewtime (sum) for the 100 pageviews is 200 seconds.
How is a client defined?
In the first step, the presence of a cookie in the request is checked. Two types of cookies are possible, either a conventional, third-party HTTP-cookie (i00) or
a cookie passed via URL-Parameter. The i00-cookie has a higher priority, i.e. it will always be used when present while the cookie set via URL is intended
to cope with low third-party cookie acceptance. It will be set if possible (e.g. html5 cookie) and used if no i00-cookie is available.
If no cookie can be set an "ident" as browser-"fingerprint" (combination of IP-address and user agent info) is created.
Two session containers are created, one for "idents" without cookies and one for those with a cookie. A client may move between the two types.
Keywords in this context are the evolving of a session (first contact without cookie, following by contacts with set cookie) and session uniqueness.
- If no valid cookie is contained, a new session is established.
- If a session that is assigned to a certain "ident" can be found, the event is added to this session.
- Otherwise a new session is created and returned.
Conclusion: Client = the same cookie or same browser "fingerprint" (combination of IP-address and user agent info)
How is a session defined?
The metric “session” is used in our measurement system.
Difference to other system that count “visits”: The metric "session" is counted every single hour, whereas the metric "visit" is counted only once for the certain hour when the usage begins.
A session is a collection of events (like page impressions) with the same cookie or fingerprint (combination of IP-address and user agent info), if the cookie is missing.
Sessions can be computed:
- Within a single web site (the standard)
- Across all web sites (networks)
There is no logout, so a timeout is used. In a single session the time between two events is less than 30 minutes.
So after an idle time of 30 minutes a new session is initiated. (following international standards)
The following information is provided for every session
- the start time of session,
- the time of the last event in the session,
- the signature of the session, formed as an MD5 hash of the user agent and the IP-address,
- the cookie of the session, if available
- the number of page impressions
- the external referrer at beginning of the session
- a list of (dimensional) properties of events (such as the pixel code)
- a list of properties of the session (references to dimensions, which are stored once per session only, such as user agent, geo-location, screen resolution)
- a list of dates of events
Conclusion: The session context is kept over the switch of the hour as long as the idle time between user interactions is not longer than 30 minutes
How will Adblock or similar tools influence the tracking?
What it is and how it operates:
Ad-blocker predominantly affects web browsers and runs as an extension in this environment:
http://en.wikipedia.org/wiki/Adblock_Plus
We can of course not be completely aware of every browser-addon or privacy-list out there that is blocking website tracking.
The most important question in the context of Adblock Plus is if there is a domain entry in https://easylist-downloads.adblockplus.org/easyprivacy.txt which corresponds to your counting domain used for a project.
Hence, if there is an entry that serves to block everything to and from the domain that you use for counting no tagged data will be returned to the measurement system.
What can we do about this?
There is not currently a way to circumvent this issue, and all tracking systems will be affected similarly.
We do not have a feel for the levels of usage although we can point out, awareness of such programs is on the rise.
The most practicable solution to this would be changing to another domain name (to which we would send requests).
However, this might prove only temporary because the new domain may also be added to the list very quickly again.
In conclusion: we are aware that it happens, but there is very little we can do about it.
Fraud Prevention
Site centric measurement system can be subject to fraud by the automated generation of usage or by introducing the tag in pages that are not actually part of the measurement system.
A line of counter measures can be configured:
| Measure | Description |
|---|---|
| IP Black List | IP-Address-Ranges can be excluded from the measurement |
| UA White List | Only “well-formed” user agents are allowed |
| Bot Black List | System support for “robot-lists” and “robots.txt” |
| Local List (Valid Referrer) | Referrers are checked for validity to make sure that only legitimately tagged pages are counted |
| PageView Threshold | A threshold for the minimum time between two page impressions can be set |
Client-Resolving
In the data processing there is a single column with the Client ID and it can (theoretically) contain any identifier for a browser or any device (both mobile and computer),
ranging from:
- cookies to browser fingerprint in a browser scenario,
- Apple IDFA, Apple IDFV, mac address (back when this was still allowed), Google Advertising ID (GID), Android ID to UDID in a mobile context
The different ID’s have different characteristics:
- Some are 100% unique and some are not, like cookies versus browser fingerprints.
- Some identify a device, while others identify only an app, like IDFA versus IDFV.
- Some are 100% unique but it is unclear where they are stored. (e.g. cookies which can reside in a browser but also inside an app)
- Some can be considered persistent (mac address), and some are almost persistent (IDFA, GID), and still some others are not persistent at all (browser fingerprint).
Internet-Client-Resolving
In the first step, the presence of a cookie in the request is checked. Two types of cookies are possible, either a conventional, third-party http-cookie (i00) or
a cookie passed via URL-Parameter. The i00-cookie has a higher priority, i.e. it will always be used when present while the cookie set via URL is intended
to cope with low third-party cookie acceptance. It will be set if possible (e.g. html5 cookie) and used if no i00-cookie is available.
If no cookie can be set an "ident" as browser-"fingerprint" (combination of IP-address and user agent info) is created.
Two session containers are created, one for "idents" without cookies and one for those with a cookie. A client may move between the two types.
Keywords in this context are the evolving of a session (first contact without cookie, following by contacts with set cookie) and session uniqueness.
- If no valid cookie is contained, a new session is established.
- If a session that is assigned to a certain "ident" can be found, the event is added to this session.
- Otherwise a new session is created and returned.
Conclusion: Client = the same cookie or same browser "fingerprint" (combination of IP-address and user agent info)
Web ID Priority a.k.a. Client Cascade
| Priority | ODDU Variable Name | Platform | Description |
|---|---|---|---|
| 1 | i00 | Web | Identifier for Browser Client = http cookie |
| 2 | c | Web | Identifier for Browser Client = URL cookie (HTML5 cookie) |
| 3 | signature | Web | Identifier for Browser Client = Combination of IP-address and user agent info |
App-Client-Resolving
Identifying mobile iOS Users
Apple devices are identified with the Advertising ID (IFA) and the ID for Vendors (IFV) and the MAC address (prior to iOS version 6).
Both the IFA and IFV get encrypted and truncated (to the first 64 bits) in the app library while it is running; it is not stored.
This is still enough to be unique, while at the same time making it impossible to track it back to the origin.
The ID, “as is”, is never sent to the collection system, it does not leave the device.
Advertising ID
The Advertising ID is a unique identifier that is available to all app developers in order to identify users. It is unique, but it can be reset by the user.
It is possible for the user to turn off the Advertising ID. However, we understand that we are still allowed to read use this ID for measurement purposes.
According to the information presented at this URL: https://developer.apple.com/library/ios/documentation/AdSupport/Reference/ASIdentifierManager_Ref/index.html
for “estimating the number of unique users”.
ID for Vendors
The ID for Vendors is an identifier that is available to every app vendor. Each device has a unique ID for every vendor that has one or more apps installed on the device.
Vendors cannot read other vendors' device ID's.
Mac Address (deprecated)
Identifying mobile Android Users
Android devices are uniquely identified with the Android ID and the UDID.
The Android ID gets encrypted and truncated (to the first 16 bits) in the app library while it is running; it is not stored.
This is still enough to be unique, while at the same time making it impossible to track it back to the origin.
The Android ID, “as is”, is never sent to the collection system, it does not leave the device.
Android ID
The Android ID is a unique identifier that is available to all app developers in order to identify users. It is unique, but it can be changed on rooted devices.
It also changes when a device is reset to factory default or a new ROM is installed.
Google Advertising ID
The advertising ID is a unique, user-resettable ID for advertising, provided by Google Play services.
It gives users better controls and provides developers with a simple, standard system to continue to monetize their apps.
It enables users to reset their identifier or opt out of personalized ads (formerly known as interest-based ads) within Google Play apps.
UDID
The UDID is unique, but it comes from the phone function of a device. This means that wifi-only devices don't have this. Also: this requires “READ_PHONE_STATE” permission.
Mobile ID Priority a.k.a. Client Cascade
In order to do counting of aggregated unique visitor and also to provide a hook with which to retrieve panelists from the census,
one identifier is picked out of all available and one is used for the count and to identify a device/app with. This one is called the Client ID.
There is a decision-cascade that prioritizes the available ID’s, in order to decide on which ID to use as the so-called final “Client ID”.
This “Client ID” is the best possible, most persistent, most unique identifier for a certain device.
The current cascade of priority for mobile apps is:
| Priority | ODDU Variable Name | Platform | Description |
|---|---|---|---|
| 0 | kid | Android/iOS | Kantar's own Identifier |
| 1 | pifv | iOS | Identifier for Vendor (IDFV) coming via URL-scheme for VirtualMeter |
| 2 | paid | Android | Android ID (AID) coming from the URL-scheme for VirtualMeter |
| 3 | ai | iOS | Apple Advertising Identifier (IDFA) (SDK support terminated in Sept 2020) |
| 4 | mid | iOS | Mac Address (deprecated) |
| 5 | aid | Android | Android ID |
| 6 | gid | Android | Google Advertising Identifier |
| 7 | did | Android/iOS | Device ID (UDID) |
| 8 | ifv | iOS | Identifier for Vendor (IDFV) |
| 9 | eid | Windows/MacOS | Identifier on Electron = Hardware ID |
Our mobile libraries try to get as much identifiers as allowed by terms & conditions of the manufacturer and by privacy regulations.
Furthermore, some identifiers can be switched off by the user, some are only available on older versions of an OS,
some are only available on newer versions of an OS, etc…
Geo-location Attribution
Every internet-capable device has a unique IP-address. The allocation of these IP-addresses is handled by the Internet Assigned Number Authority, http://www.iana.org/.
Big blocks of the available IP-address space are assigned first to one of the regional institutions such as RIPE NCC (for Europe, the Middle East, and Central Asia),
and from there to Internet Service Providers (ISP), and eventually from there to individual private and commercial users.
Through the administration of IP-address allocation, it is also possible to trace IP-addresses back to a geographical location.
Third party databases exist for this purpose.
In order to do Geo-location-attribution, Kantar - Media Division has a subscription for a third party database from dp-ip.com https://db-ip.com
The Geo-location is done at the time of collection of the data. (Mainly because EU and local privacy laws do not allow the storage of IP-addresses)
When a measurement request comes into the collection servers, the originating IP-address of the device
is immediately processed into two different geographical values:
- geographical location of the device,
- ISP of the device.
Kantar - Media Division updates the Geo-location databases for our clients in the first week of every quarter.
Device Type Recognition
Introduction
The Kantar Device Type Recognition is done by means of analyzing the User Agents of all devices that come into contact with the measurement system.
The User Agent is a standard part of the HTTP-protocol, i.e. every device has one. From Wikipedia:
In HTTP, the User-Agent string is often used for content negotiation, where the origin server selects suitable content or operating parameters for the response.
For example, the User-Agent string might be used by a web server to choose variants based on the known capabilities of a particular version of client software.
The concept of content tailoring is built into the HTTP standard in RFC 1945 "for the sake of tailoring responses to avoid particular user agent limitations.”
User Agent Formatting
User Agents follow standard formatting rules that are defined at http://tools.ietf.org/html/rfc7231#section-5.5.3. ![]() Note that users as well as App developers can customize the User Agent of their browser or app, thus making it unrecognizable by Kantar's default filter method.
Note that users as well as App developers can customize the User Agent of their browser or app, thus making it unrecognizable by Kantar's default filter method.
From User Agent to Device Type
The device type on which a webclient is running is not explicitly present in the User Agent. Kantar assigns a device type based on the information that is present in the User Agent.
This is done by means of a regular expressions script that checks the User Agents for information such as the Operating System, Browser or Client Name, or other specific strings
that are known to differentiate between device types. For example, Android and iOS have specific strings in the User Agent to help differentiate between smartphones and tablets.
The different device types that can be found in Kantar data are:
| Devise Type | Description |
|---|---|
| n.a. | When no User Agent can be found. This is usually only a very small percentage of all devices. |
| pc | Regular computers and laptops. |
| mobile | Smartphones. Both apps and browsers on smartphones are identified as "mobile". |
| tablet | Tablets. Both apps and browsers on tablets are identified as "tablet". |
| game-console | XBox, Playstation, Switch |
| set-top-box | Devices such as Roku streaming devices. |
| smart-tv | Apps on smart TV's or big screen devices. |
Updates and Maintenance
Kantar maintains and frequently updates the User Agent recognition scheme on a quarterly schedule.
Big changes in the industry like new versions of browsers, new versions of Android and iOS, are followed up on.
If a change to the device type recognition is needed, it is done so ad-hoc.
Additionally, if clients require device type recognition for specific custom User Agents, Kantar can offer to build that into the system as well.
Kantar Browser Meter
Purpose of the Kantar Browser Meter (a.k.a KBM)
The HTTP cookie (as third party measurement cookie) is no longer a reliable identifier in common Web measurement scenarios
The KBM allows for tracking (sniffing) all browser called URLs
KBM can react on these caught URLs and send them to a different collection endpoint
The KBM allows Kantar to generate a unique Browser ID and link this browser marker to a specific panel when combined with Panel ID
The target group of the KBM are Kantar online panelists
Goal: Enriching an existing browser measurement with a reliable identifier
General Use Case
The simplest use case: KBM is scanning for an existing tag and modifies it by adding the KBM Browser ID
The identification of a panelist takes already place outside of the KBM, e.g. the measurement request already contains panelist information
KBM is enriching an existing panel browser measurement with a reliable identifier (Browser ID)
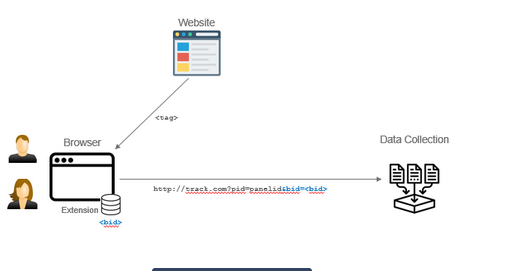
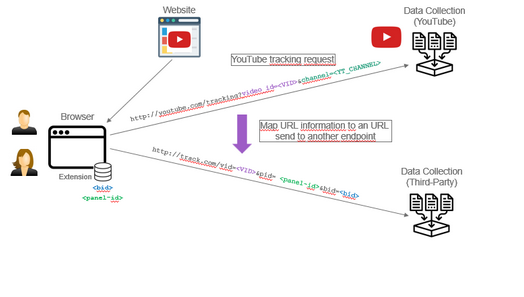
YouTube Use Case
The YouTube use case:
KBM is scanning for YouTube’s tracking URL (ptracking),
KBM is extracting various information from that YouTube URL
KBM is mapping the URL request to another endpoint
This mapping functionality is flexible and configurable to send the data to another measurement system in a required format
The extracted information is enriched with a Panel ID and the KBM Browser ID
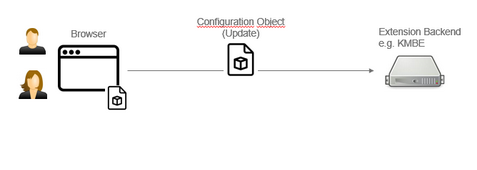
KBM Configuration Object
The KBM is delivered per-configured to download spaces or stores.
If a KBM back-end is available, KBM can receive messages and updates its configuration object.
This allows for changes at very short notice as long as they do not affect any internal functionality of the KBM.
The Configuration Object contains:
all Tracking URLs
customized popup widget configuration
configurable features inside of the popup
Sleep mode
OptOut / OptIn
Some behavior configurations
A predefined configuration object will be generated for the different panels before deployment (e.g. into the stores)
KBM Language Settings
Localized translations are set depending on the chosen browser language.
KBM Life-Cycle Events
Kantar has currently defined the following life-cycle events.
By using the Configuration Object a URL endpoint (e.g. KMBE) can be defined to which the information about these events can be sent.
Installation
Sleep mode on/off
OptOut / OptIn
Uninstall
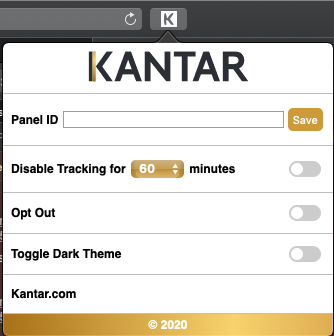
Sleep Mode
The panelist can switch off the KBM tracking for a certain period of time.
During this time, no tracking is performed nor messages are received.
The sleep mode can also be terminated before the time is up.
Input Panel
Allows the user to manually enter a panel ID, which is then stored in the KBM.
This allows for a rudimentary check of this ID.
OptOut / OptIn
A feature to avoid possible de-installations by panelists.
The OptOut / OptIn behaves the same way as the sleep mode only with infinite time.
More Info about the different functions like Sleep Mode etc. can be found in the manuals provided here:
https://kantarmedia.atlassian.net/wiki/spaces/EVME/pages/2641461519/Browser+Meter+Release+Notes
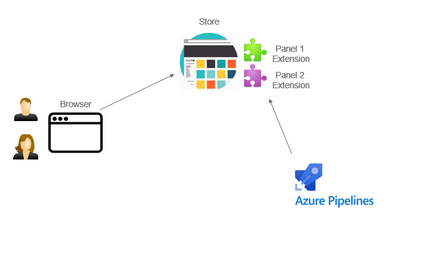
KBM Deployment and Installation
Kantar delivers the KBM to Kantar download spaces or browser stores via Azure pipelines
The model of the KBM is currently chosen so that a specific KBM version supports a panel
The KBM for Chrome must be distributed via the Google store
However, it isn't listed in the store search, which means that a panelist must know the corresponding download URL for installationThe KBM for Safari and Firefox can also be distributed outside of the appropriate browser store
User Centric Measurement
Modern tracking systems in the Internet log the usage of users using different identification techniques.
Most (if not all) of these techniques do not directly identify the user = (human being) itself but the program or computer that is used to fetch the content.
There are several mechanism available to do this identification: HTTP-Cookies, Flash-LSO, the more modern HTML5 Local Storage and different types of fingerprinting
where multiple characteristics are combined to generate an identifier.
The tracking systems record the webpages or videos visited, the time spent on those pages/videos, the geographic origin and
lots of other metrics derivable from the information transmitted by the users. But those systems do not have and provide clear information about the user itself.
To gather more detailed, user centric information, most common panels (Web-Panel, Panel App for mobile devices) or software meters (Focalmeter and Virtualmeter) are used.
These panels consist of a set of well known persons or households, that normally fill out some kind of survey that contains questions
about sociol-demo-graphical and technical attributes. The persons or households get an anonymous panel-ID to identify themselves and their activities.
An anonymous panel-ID can consist of:
- A personalized panelist-ID
- A combination of a household-ID and a set-ID
- A combination of a panelists-ID and device-ID and browser-ID
This ID stands for a sociol-demo-graphical profile and allows - if known - a combination of the tracked usage with the given sociol-demo-graphical attributes:
when the panelist transfers its identifier to the tracking system, the system is able to set up a mapping between its internal tracking-identifier and the panel-identity.
This way, the recorded usage can be identified and assigned to the related panelist or panel household.
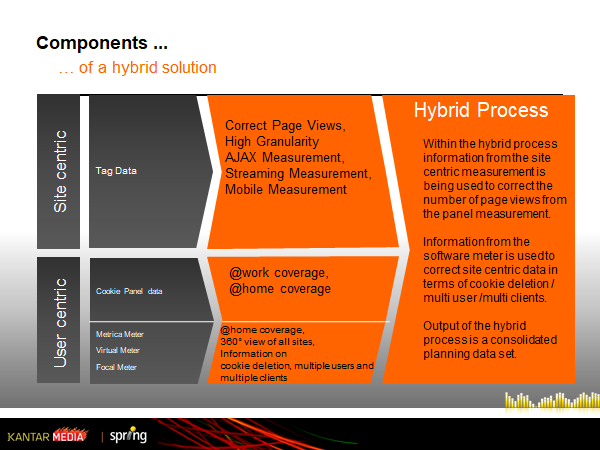
Hybrid Measurement
Video Tagging (SDK) used in conjunction with Kantar’s metering technologies like VirtualMeter and FocalMeter delivers
granular and accurate viewing data for programmes and advertising across all platforms and devices, enabling the creation of currencies.
It enables broadcasters to:
- Understand what and how many people are consuming video content across different online platforms.
- Reinforce the value of their multi-screen audiences
- Optimize media investment by finding smarter and more cost-effective ways to reach specific audiences.
Collection Server (Box)
The Tags send the registered information (injected metadata info = tagged info, Internet-transaction-available info) to the measurement boxes as either HTTP- or HTTPS-calls.
Measurement boxes are single height unit servers deployed locally or virtual machines in cloud environments. They contain a proprietary web server that is able
to register and respond to several thousand HTTP-calls per second. It is hardened in terms of security and tampering, thus contributing to the integrity of the measurement.
The typical response times on HTTP-calls are ~ 70 ms.
Data Processing (Cluster)
A cluster based back-end architecture ensuring short response times and rapid aggregation of data.Data from the collection servers (boxes) is being “polled” by a centralized system (collector) every 10 minutes in a transaction safe manner (local buffering).
The Analytic Cluster is built on the hadoop cluster architecture. A proven technology for processing large amounts of data.
It allows for rapid, easy and cheap scaling and provides superior fail-safe mechanisms (distributed data).
The cluster is hosted in a high security data center on our premises and is connected to the “rest” of the Internet by 3 x 64 Gigabit lines.
Data Export
Aggregated Data
Based on the content tagged aggregated export data is delivered on SFTP download locations.
Export Report Data
Export reports contain the major KPI figures for analysis and reporting purposes:
| Type of Measurement | Platform | KPI-Figures |
|---|---|---|
| IAM | Web | PageViews, Sessions, Clients, PageViewtime |
| IAM | App | Events, Sessions, Clients, EventTime |
| VAM | Web/App | VideoViews, Sessions, Clients, TotalPlaytime |
Possible data delivery frequencies:
- daily
- weekly
- monthly
Target Data
| Type of Measurement | Platform | Context | Identifier | KPI-Figures |
|---|---|---|---|---|
| VAM | Web/App | per Player Platform | Cookie/Mobile Identifier | VideoViews per Program Name (Video-ID), Device Type, Player Info, TotalPlaytime per Video Viewing Session, Amount of Occurrence |
Possible data delivery frequencies:
- hourly
- daily
Session-Based Data
Based on the content tagged session-based export data is delivered on SFTP download locations.
Session-Based Full Census Data
In addition to the daily, weekly and monthly viewing reports for the website or video platforms (Export Report Data), a customer requirement exists
for the full set of processed data to be available for data integration purposes. This data can be delivered in the form of viewing ‘sessions’ inclusive of the metadata.
Each viewing session contains a start and end time (or duration) of viewing and a position in content related to that viewing for use in further data integration.
| Type of Measurement | Platform | Context | Identifier | KPI-Figures |
|---|---|---|---|---|
| IAM | Web | per Website | Cookie | PageViews, Start- and End-time of Viewing, UA Info, visited URL, Geolocation |
| IAM | App | per App-Name | Mobile Identifier | Events, Start- and End-time of Viewing, UA Info, Geolocation |
| VAM | Web/App | per Player Platform | Cookie/Mobile Identifier | VideoViews per Program Name (Video-ID), Start- and End-time of Viewing, UA Info, Geolocation, Player Info, Position on Video, TotalPlaytime per Video Viewing Session |
Possible data delivery frequencies:
- hourly
- daily
Session-Based Sample of Full Census Data
Calibrating the panel data to the full census data would require correcting the panel data by adding viewing. The viewing to be added is picked up from the full census data.
Since full census data can be extremely high in volume, data integration purposes may need just a sample of the full census viewing that is representative (of the census).
These samples of full census viewing should be sufficient for correcting the panel data.
| Type of Measurement | Platform | Context | Identifier | KPI-Figures |
|---|---|---|---|---|
| IAM | Web | per Website | Cookie | PageViews, Start- and End-time of Viewing, UA Info, visited URL, Geolocation |
| IAM | App | per App-Name | Mobile Identifier | Events, Start- and End-time of Viewing, UA Info, Geolocation |
| VAM | Web/App | per Player Platform | Cookie/Mobile Identifier | VideoViews per Program Name (Video-ID), Start- and End-time of Viewing, UA Info, Geolocation, Player Info, Position on Video, TotalPlaytime per Video Viewing Session |
Possible data delivery frequencies:
- hourly
- daily
Panel Data
Panel data output consists in two forms of data sets:
Panelists data
Panelist file contains a collection of registered panelists transferred by registration web-portals or mobile registration applications (Panel Apps, VirtualMeter)
or meter-based registration (FocalMeter). It contains a combination of Panel-ID's and device identifiers and a recorded registration time-stamp.
Possible data delivery frequencies:
- daily
- weekly
- monthly
Usage Data
The recorded usage (web site visit or video viewing) of an specific device identifier can be identified in the full census data and then be assigned to the related panelist or panel household.
contain the major KPI figures for analysis and reporting purposes:
| Type of Measurement | Platform | Context | Identifier | KPI-Figures |
|---|---|---|---|---|
| IAM | Web | per Website | Cookie | PageViews, Start- and End-time of Viewing, UA Info, visited URL, Geolocation |
| IAM | App | per App-Name | Mobile Identifier | Events, Start- and End-time of Viewing, UA Info, Geolocation |
| VAM | Web/App | per Player Platform | Cookie/Mobile Identifier | VideoViews per Program Name (Video-ID), Start- and End-time of Viewing, UA Info, Geolocation, Player Info, Position on Video, TotalPlaytime per Video Viewing Session |
Possible data delivery frequencies:
- hourly
- daily
- weekly
- monthly
Display Tools
A modern and user-friendly browser-based interface that allows for deep drill-downs into the sites data